|
I am a Research Scientist at Adobe Research. I completed my Ph.D. at CUHK and was a research assistant at the BAIR, Berkeley. My research interests lie in VLMs, Agents, and AIGC, including applications such as image and video generation, editing, and manipulation. We are hiring self-motivated and creative interns. If you are interested in an Adobe internship or a university collaboration, please feel free to contact me. |

|
|
|

|
Shaoteng Liu, Tianyu Wang, Jui-Hsien Wang, Qing Liu, Zhifei Zhang, Joon-Young Lee, Yijun Li, Bei Yu, Zhe Lin, Soo Ye Kim, Jiaya Jia CVPR, 2025. arXiv / Project Page / Video / Data / Adobe Firefly Adobe News / Twitter / 机器之心 We demonstrate that through a careful design of a generative video propagation framework, various video tasks can be addressed in a unified way by leveraging the generative power of such models. |

|
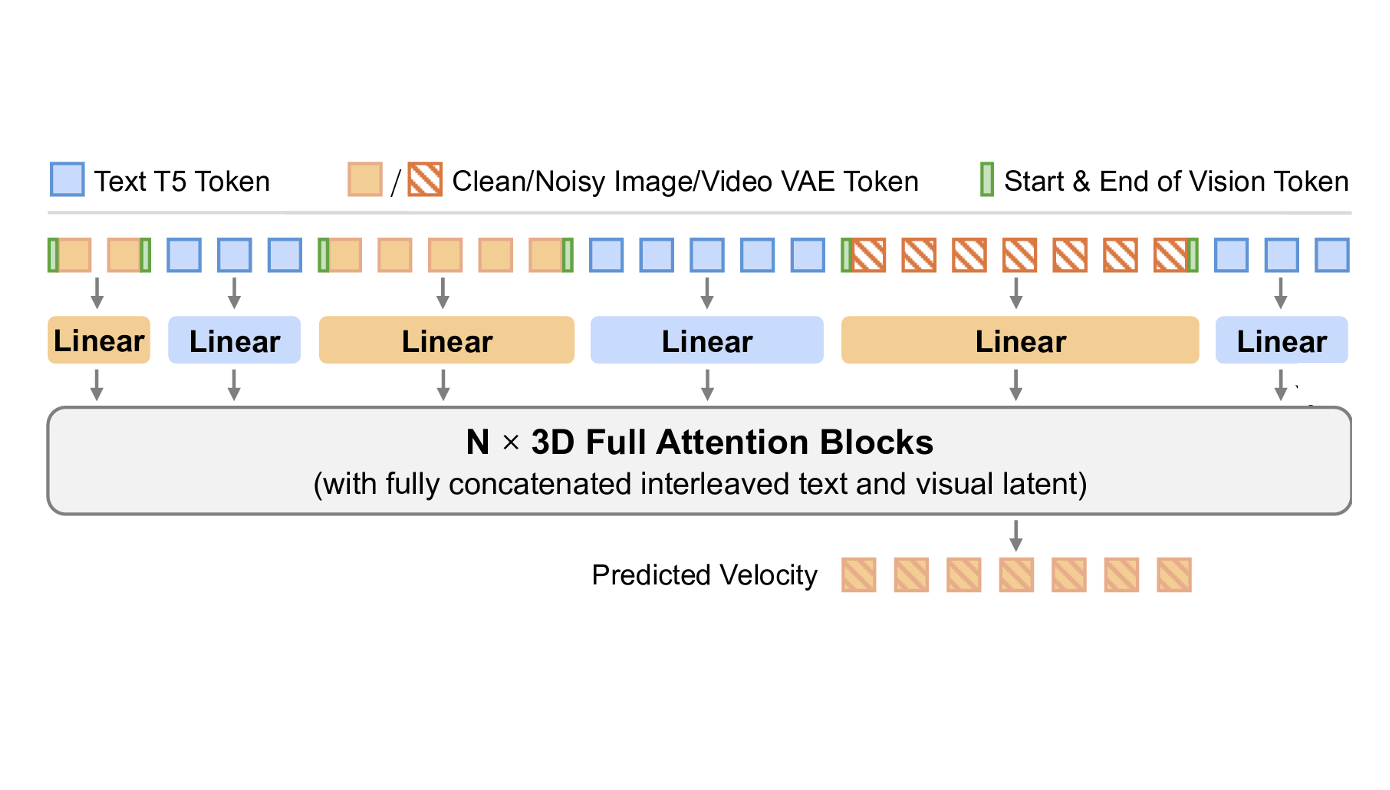
Xuan Ju, Tianyu Wang, Yuqian Zhou, He Zhang, Qing Liu, Nanxuan Zhao, Zhifei Zhang, Yijun Li, Yuanhao Cai, Shaoteng Liu, Daniil Pakhomov, Daniil Pakhomov, Zhe Lin, Soo Ye Kim, Qiang Xu Preprint, 2025. arXiv / Project Page / Code 
EditVerse unifies a diverse range of generation and editing tasks for both images and videos within a single, powerful model. |

|
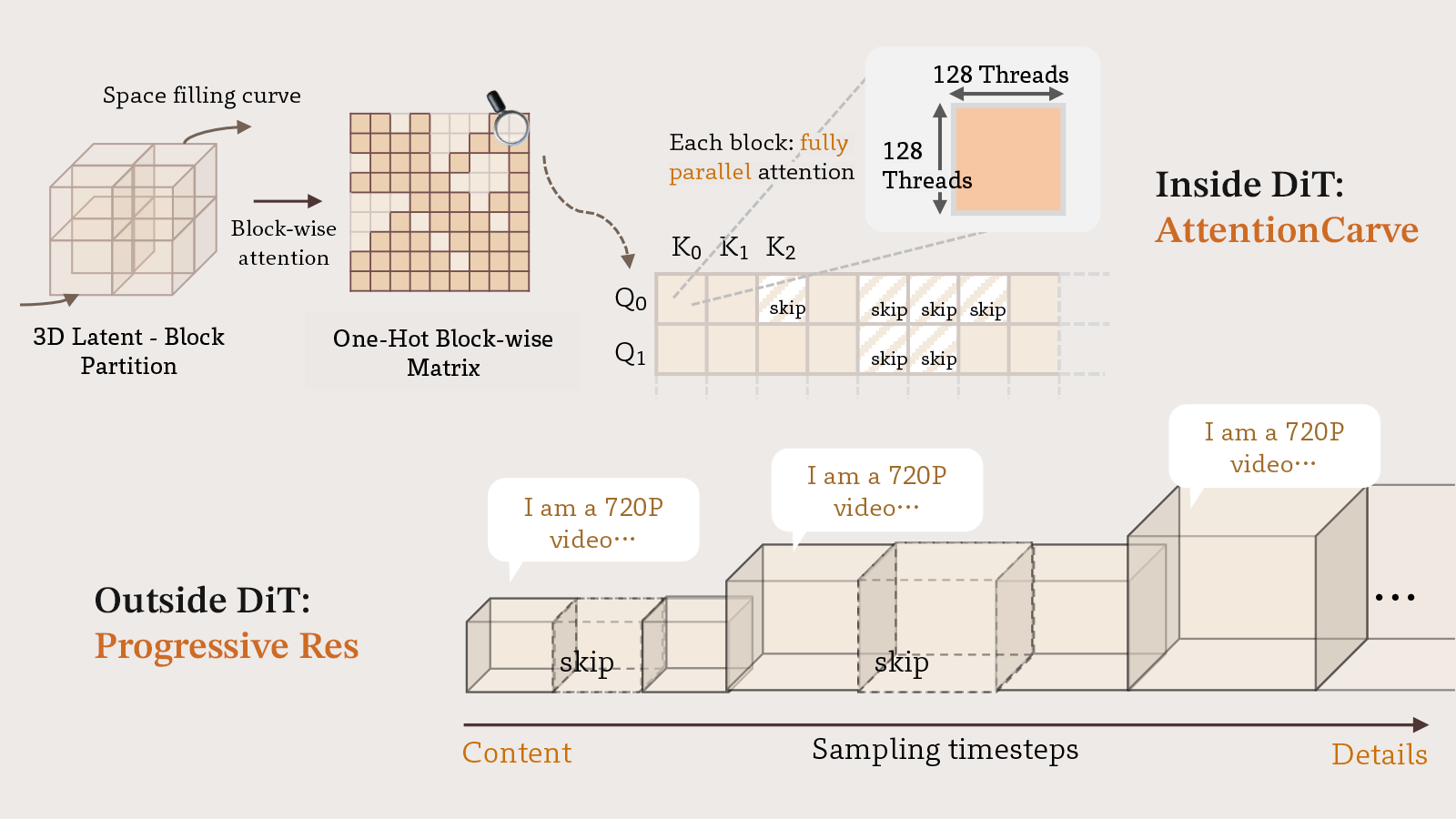
Yuechen Zhang, Jinbo Xing, Bin Xia, Shaoteng Liu, Bohao Peng, Xin Tao, Pengfei Wan, Eric Lo, Jiaya Jia NeurIPS, 2025, arXiv / Project Page / Code 
Jenga accelerates HunyuanVideo by 4.68-10.35× through dynamic attention carving and progressive resolution generation. |

|
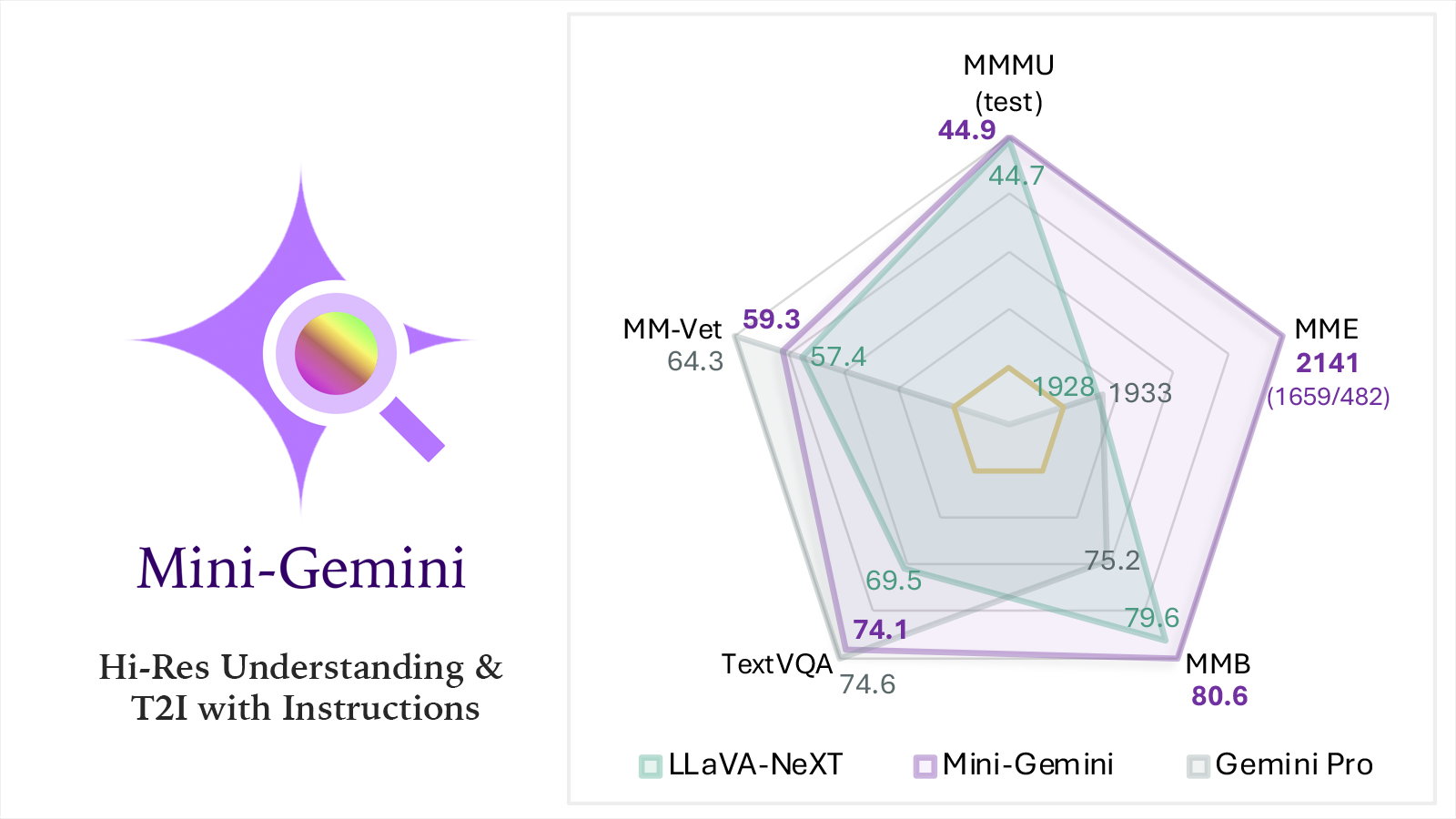
Yanwei Li*, Yuechen Zhang*, Chengyao Wang*, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, Jiaya Jia TPAMI, 2025. arXiv / Project Page / 机器之心 / Demo / Model / Data / Code 
Mining potential of open-source VLMs! Mini-Gemini is a novel framework ranges from 2B to 34B VLMs for hi-resolution image understanding. It has a impressive OCR capability, and can generate HQ images powered by its multi-modal reasoning ability. |
|
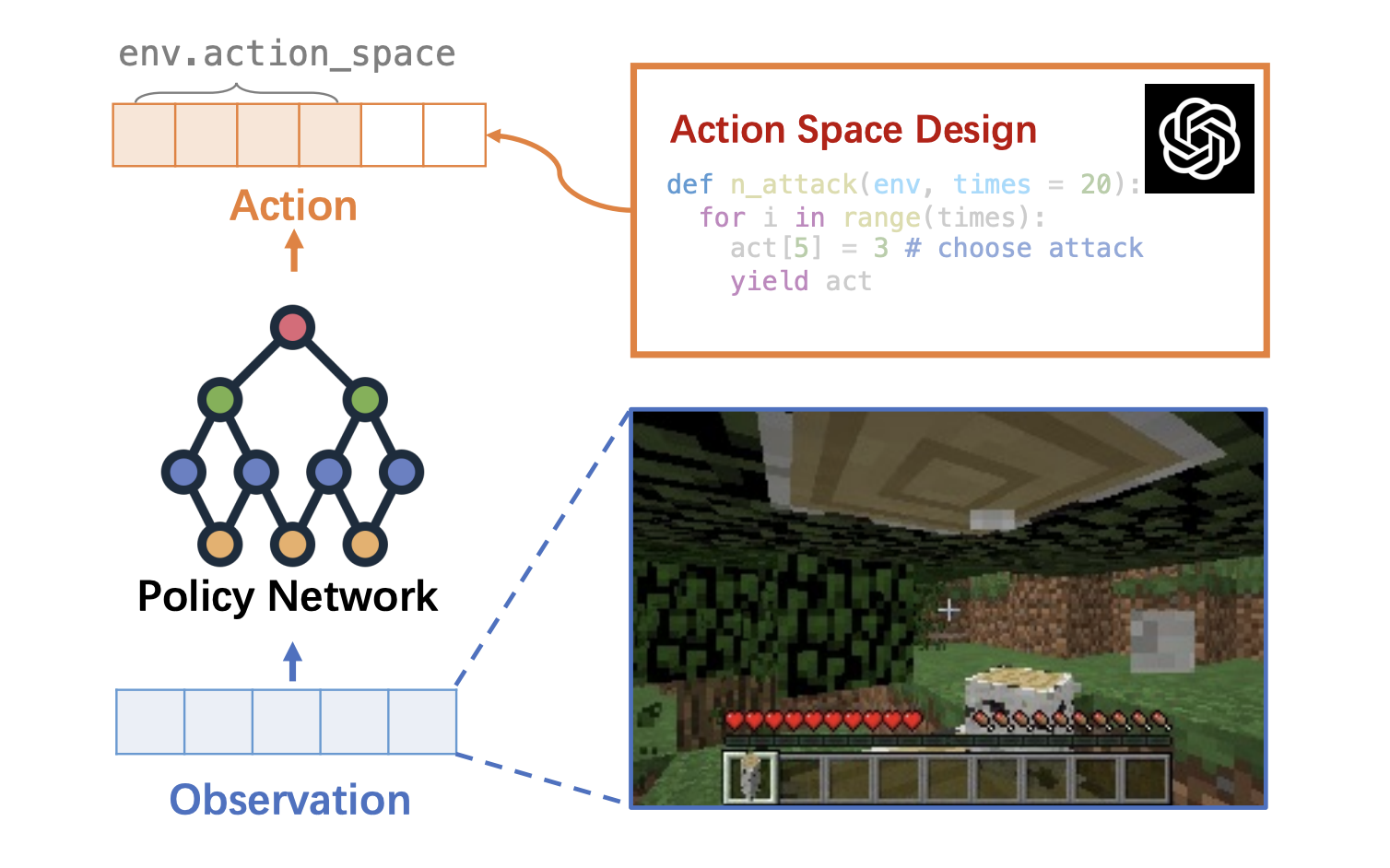
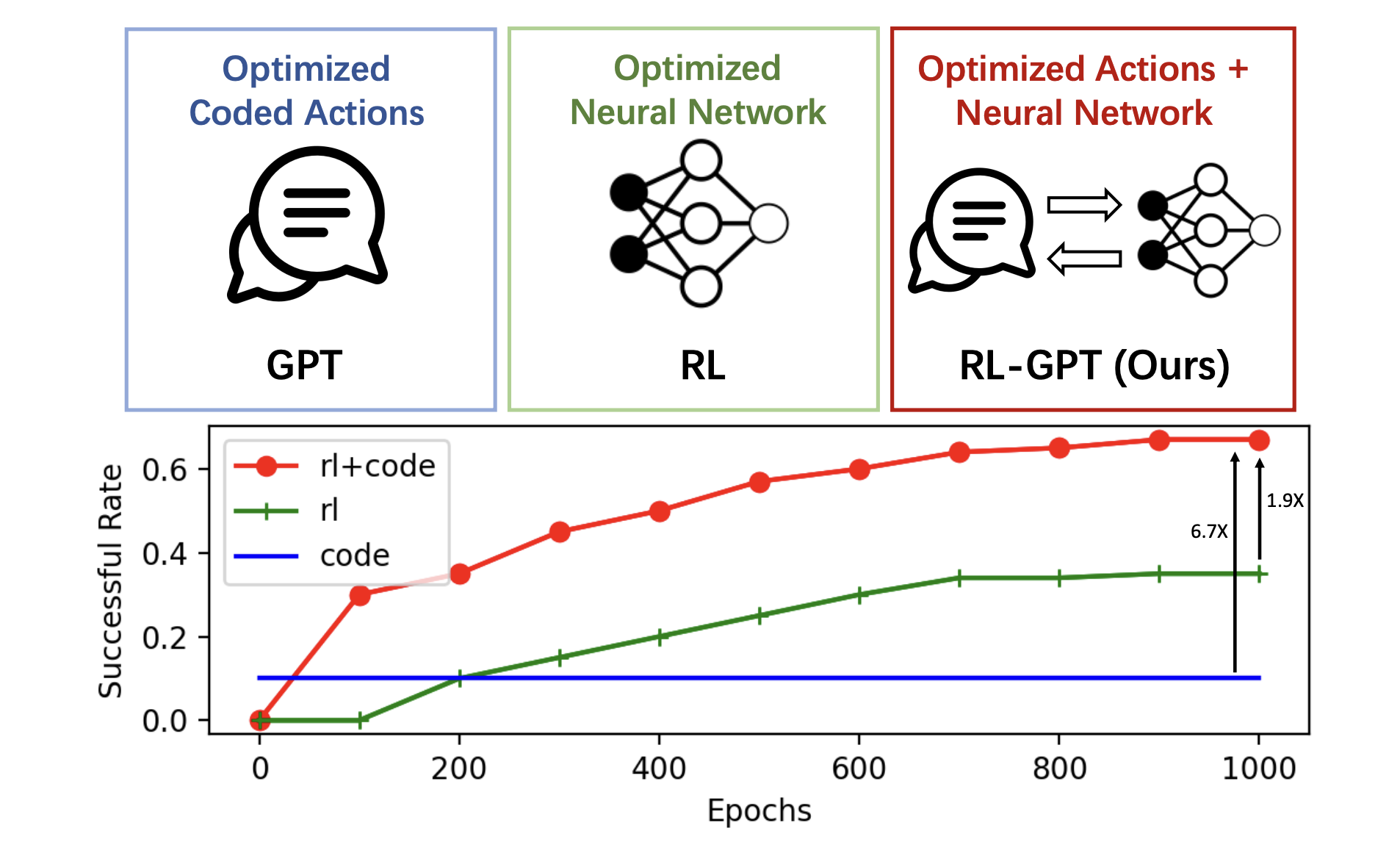
Shaoteng Liu, Haoqi Yuan, Minda Hu, Yanwei Li, Yukang Chen, Shu Liu, Zongqing Lu, Jiaya Jia NeurIPS, 2024. Oral arXiv / Project Page The slow agent decomposes the task and determines "which actions" to learn. The fast agent writes code and RL configurations for low-level execution. |

|
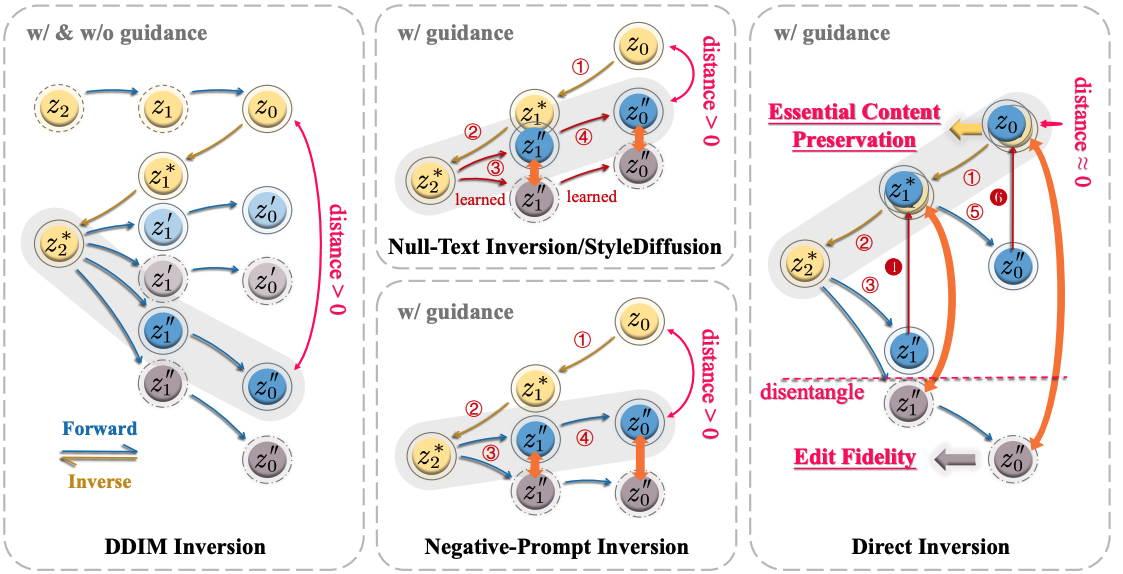
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, Qiang Xu ICLR, 2024. arXiv / Project Page / Video / Data / Code 
Rethinking the inversion process. Boosting Diffusion-based Editing with 3 Lines of Code. |

|
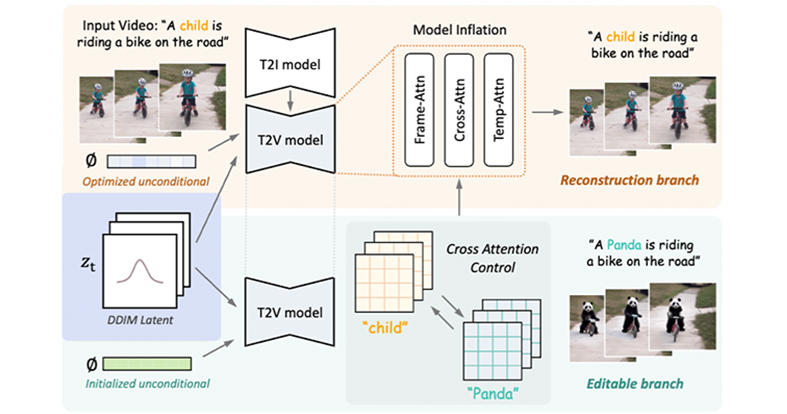
Shaoteng Liu, Yuechen Zhang, Wenbo Li, Zhe Lin, Jiaya Jia CVPR, 2024. Most Influential CVPR Papers (Paper Digest ) arXiv / Project Page/ Twitter/ Code 
Add 'Lego' attribute to the child, an edited video is generated. Powered by a novel video inversion process and cross-attention control. We also find that a Decoupled-Guidance strategy is essential for video editing. |
|
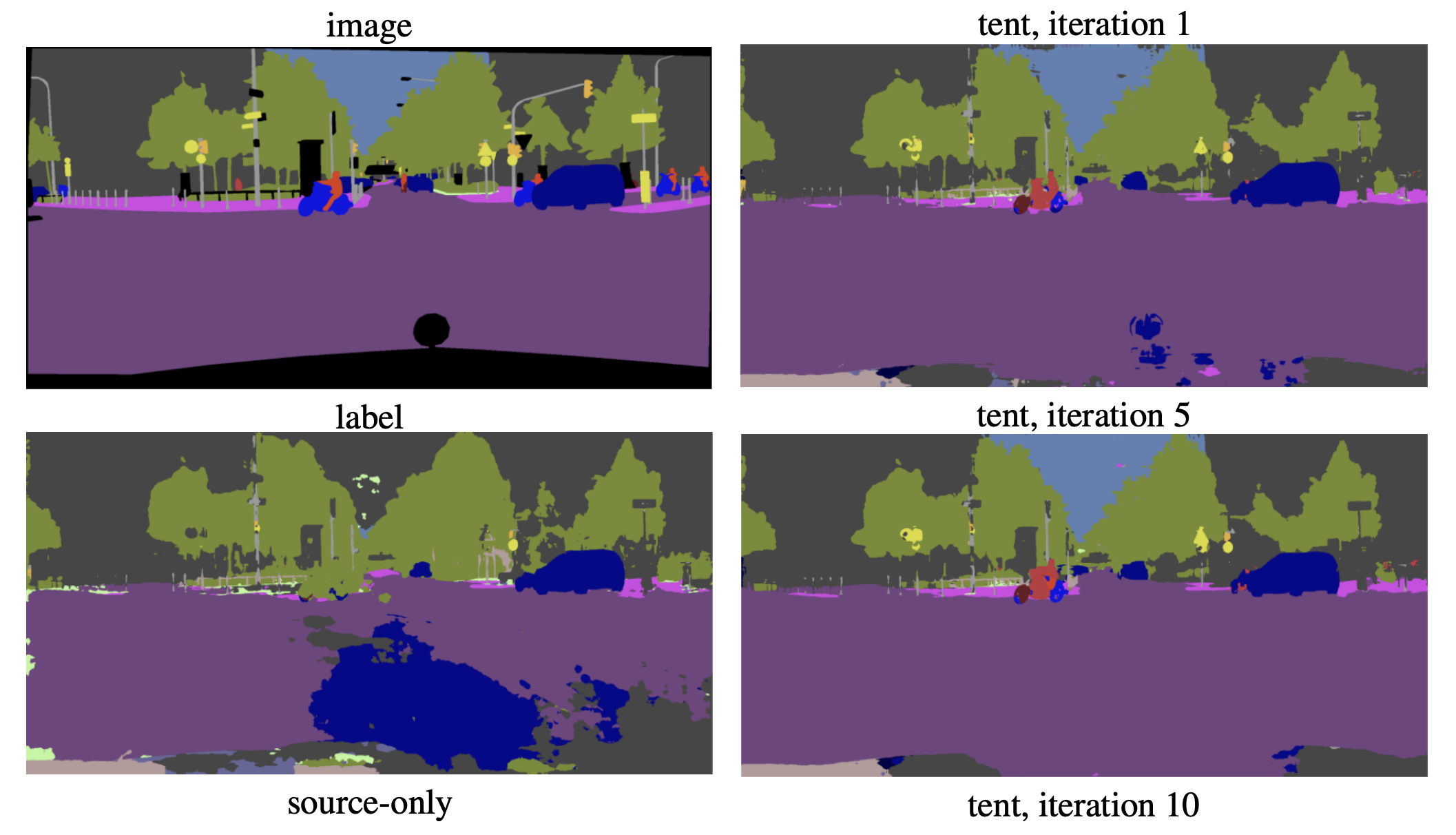
Dequan Wang*, Evan Shelhamer* Shaoteng Liu, Bruno Olshausen, Trevor Darrell ICLR, 2021. Spotlight arxiv/ Code 
Tent equips a model to adapt itself to new and different data during testing. |
|
|
Doctoral Consortium, ICCV, 2025
Excellent Teaching Assistantship, CUHK, 2023
Hong Kong PhD Fellowship Scheme (HKPFS), 2021
Vice-Chancellor’s Scholarship, CUHK, 2021
Scientist Scholarship of China (top 1%), 2019
Top 10 Undergraduate of XJTU (top 0.1%), 2019
National Scholarship of China, 2018
|
|
Reviewer: CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, AAAI, SIGGRAPH, SIGGRAPH ASIA, TPAMI
Orgnizer: HiGen, ICCV 2025 Workshop
|
|
|
ENGG5104 | Image Processing and Computer Vision | 2023 Spring ENGG2780A | Probability for Engineers | 2022 Spring CSCI1540 | Computer Principles and C++ Programming | 2021 Fall |